Jupyter Notebooks#
What is a Notebook?#
Think of a notebook as a document that you can access via a web interface that allows you to save input (i.e. live code) and output (i.e. code execution results / evaluated code output) of interactive sessions as well as important notes needed to explain the methodology and steps taken to perform specific tasks (i.e data analysis).
What is a Jupyter Notebook?#
The Jupyter Notebook is an open-source web application that allows you to create and share documents that contain live code, equations, visualizations and narrative text. Uses include: data cleaning and transformation, numerical simulation, statistical modeling, data visualization, machine learning, and much more.
The Jupyter Notebook project is the evolution of the IPython Notebook library which was developed primarily to enhance the default python interactive console by enabling scientific operations and advanced data analytics capabilities via sharable web documents.
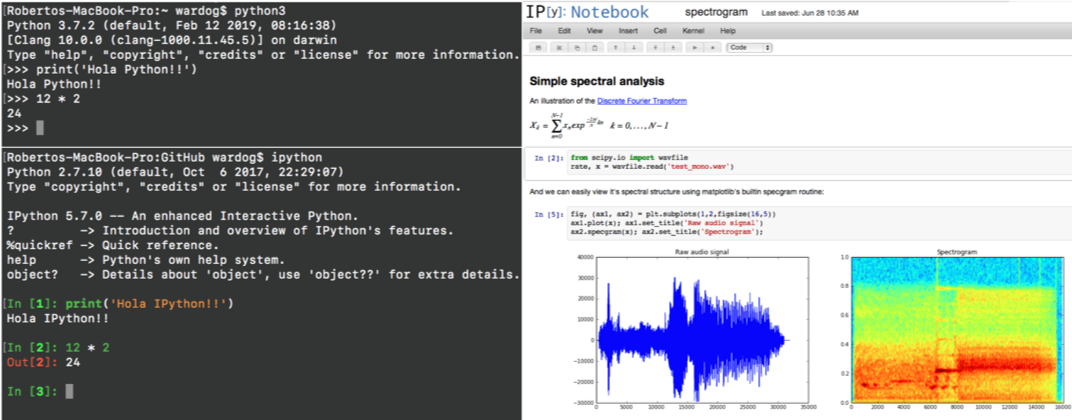
Nowadays, the Jupyter Notebook project not only supports Python but also over 40 programming languages such as R, Julia, Scala and PySpark. In fact, its name was originally derived from three programming languages: Julia, Python and R which made it one of the first language-agnostic notebook applications, and now considered one of the most preferred environments for data scientists and engineers in the community to explore and analyze data.
How do Jupyter Notebooks work?#
Jupyter Notebooks work with what is called a two-process model based on a kernel-client infrastructure. This model applies a similar concept to the Read-Evaluate-Print Loop (REPL) programming environment that takes a single user’s inputs, evaluates them, and returns the result to the user.
Based on the two-process model concept, we can explain the main components of Jupyter in the following way:
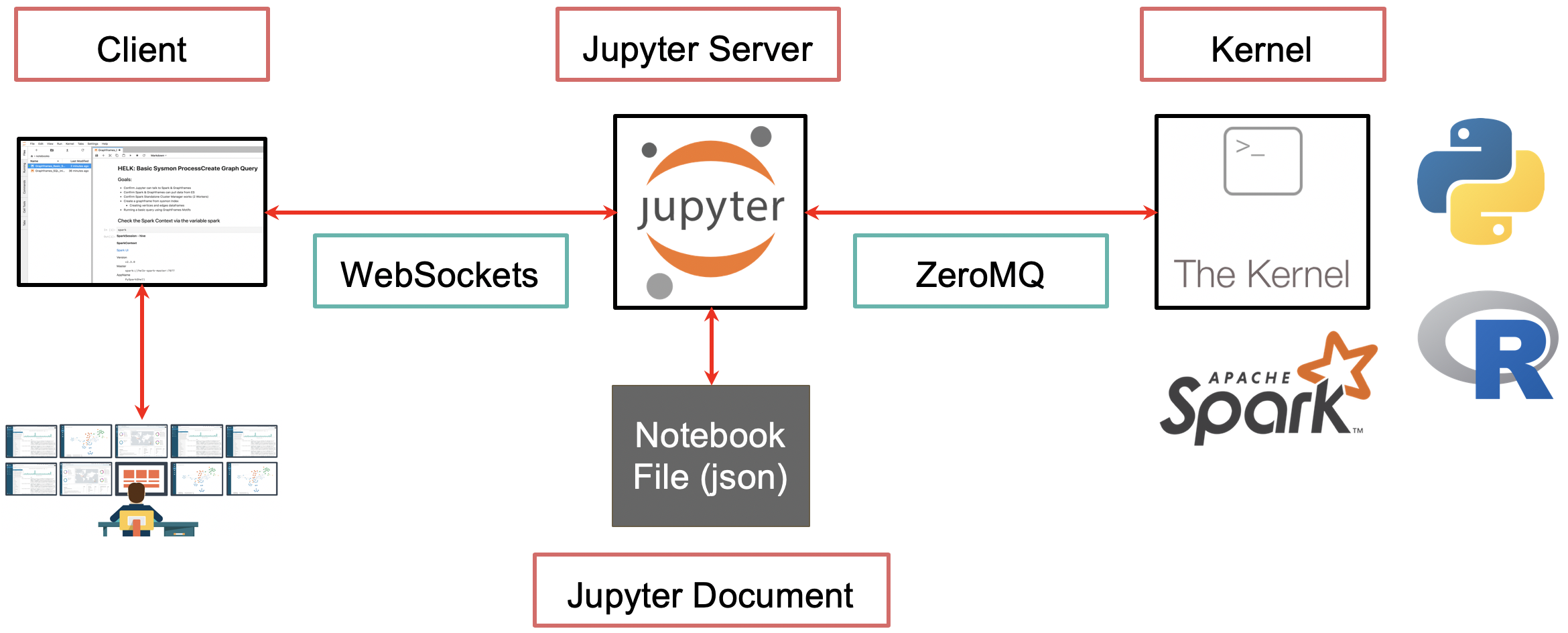
Jupyter Client#
It allows a user to send code to the kernel in a form of a Qt Console or a browser via notebook documents.
From a REPL perspective, the client does the read and print operations.
Notebooks are hosted by a Jupyter web server which uses Tornado to serve HTTP requests.
Jupyter Kernel#
It receives the code sent by the client, executes it, and returns the results back to the client for display. A kernel process can have multiple clients communicating with it which is why this model is also referred as the decoupled two-process model.
From a REPL perspective, the kernel does the evaluate operation.
kernel and clients communicate via an interactive computing protocol based on an asynchronous messaging library named ZeroMQ (low-level transport layer) and WebSockets (TCP-based)
Jupyter Notebook Document#
Notebooks are automatically saved and stored on disk in the open source JavaScript Object Notation (JSON) format and with a .ipynb extension.